In this lesson, we will explore and gain insights into an essential data structure known as hash tables. Sometimes referred to as hash maps in various programming languages, hash tables play an instrumental role in providing a practical and efficient means of organizing data.
Hash tables drive many data storage techniques and in-memory databases, powering large-scale applications such as database indexing, caches, and even some machine learning algorithms. They store data associatively, linking or mapping values to unique keys.
This lesson focuses on understanding the underlying structure and mechanics of hash tables, how they handle conflicts or collisions when multiple keys hash to the same index, and how to perform complexity analysis to understand their efficiency. By the end of this lesson, you should understand how hash tables operate and how Python dictionaries leverage the principles of hash tables.
As we delve into the world of hash tables, let's start by understanding their underlying structure. A hash table consists of an array (the actual table where data is stored), coupled with a hash function. The hash function plays a crucial role - it takes the keys as input and generates an index, mapping keys to different slots or indices in the table.
Each index of the array holds a bucket that ultimately contains the key-value pair. The pairing of keys with values enhances the data retrieval process. The efficiency of retrieving values depends on the hash function's ability to distribute data across the array uniformly.

You can also think of hash tables as hash sets storing tuples of (key, value), but this particular interface makes it less easy to use, so Python has a concept of dictionaries we will cover below.
Let's visualize this with a Python dictionary, which operates on the same principle. Suppose we have a dictionary containing student names as keys and their corresponding scores as values:
Python1# A simple dictionary illustrating the principle of hashing 2student_scores = { 'Tom': 85, 'Serena': 92, 'Alex': 78, 'Nina': 88 } 3 4# printing the scores 5for student, score in student_scores.items(): 6 print(f"{student}: {score}") 7 8# Outputs: 9# Tom: 85 10# Serena: 92 11# Alex: 78 12# Nina: 88
In this example, 'Tom', 'Serena', 'Alex', and 'Nina' are keys, while 85, 92, 78, and 88 are their associated values. Under the hood, the Python interpreter uses a hash function to assign each key-value pair to a unique address in memory.
There are instances when two different keys produce the same index after being processed through the hash function. This situation is known as a collision. When a collision occurs, we are faced with a dilemma - where do we store the new key-value pair since that index is already occupied?
Here are two common strategies to handle such scenarios:
Chaining: In this method, each index (or bucket) in the array hosts a linked list of all key-value pairs that hash to the same index. When a collision occurs, we simply go to the collided index and append the new key-value pair to the existing linked list.
Open Addressing: Upon encountering a collision, the hash table searches for another free slot or index in the table (possibly the next available empty slot) and assigns that location to the new key-value pair. This approach requires a suitable probing strategy to ensure efficient use of table space.
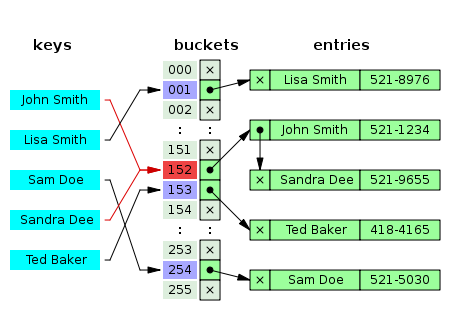
The image below provides a visual example of Chaining collision resolving method - John Smith and Sandra Dee have the same hash function result, so their entries are organized in a linked list in the corresponding bucket.
Hash tables are renowned for their efficiency and speed when it comes to data storage and retrieval. They boast constant time complexity for the operations on key-value pairs - insertion, deletion, and retrieval. This efficiency comes from a good hash function, which allows for keys to be uniformly distributed across the table and accessed directly via their indices, eliminating the need to scan through unnecessary slots.
Although hash tables generally perform robustly, situations may arise where frequent collisions occur. Such situations could deteriorate the table's efficiency and extend the time complexity to a worst-case scenario of , where is the number of keys hashing to the same index.
Python provides a built-in implementation of hash tables, known as dictionaries. Dictionaries in Python work similarly to hash tables. They allow the use of arbitrary keys to access values and handle collisions seamlessly behind the scenes, ensuring consistent and quick access to stored data.
You can create a dictionary with key-value pairs, access values using keys, and perform various operations such as adding new key-value pairs and deleting them, as demonstrated below:
Python1# Create a Python dictionary similar to a Hash Table 2book_ratings = {"Moby-Dick": 8, "The Great Gatsby": 9, "War and Peace": 10, "The Catcher in the Rye": 8} 3 4# Access a value with its key. This happens in O(1) time 5print(book_ratings["Moby-Dick"]) # Outputs: 8 6# Another way to access a value with its key is by providing the default value if the key is not there. Complexity is also O(1). 7print(book_ratings.get("Moby-Dick", 0)) # Outputs: 8 8print(book_ratings.get("Moby Dick", 0)) # Outputs: 0 9 10# Add a new key-value pair. The addition operation is also O(1) 11book_ratings["To Kill a Mockingbird"] = 9 12book_ratings["The Great Gatsby"] = 8 13print(book_ratings) 14# Outputs: {"Moby-Dick": 8, "The Great Gatsby": 8, "War and Peace": 10, "The Catcher in the Rye": 8, "To Kill a Mockingbird": 9} 15 16# Remove a key-value pair. Deletion is also a constant time operation 17del book_ratings["War and Peace"] 18print(book_ratings) 19# Outputs: {"Moby-Dick": 8, "The Great Gatsby": 9, "The Catcher in the Rye": 8, "To Kill a Mockingbird": 9}
Today's lesson has taken us on an exciting exploration of hash tables and their equivalence to dictionaries in Python. We've uncovered the intricacies of hash tables - how they manage data, prevent collisions, and their time complexity under different circumstances. Understanding these concepts is key to leveraging hash tables in different applications and scenarios in software engineering and data analysis. Now, you are well-equipped with the knowledge of what a hash table is and how to use it in real-world applications!
Now that you've journeyed through the theory behind hash tables, it's time to solidify this knowledge through hands-on experience. In the next section, we will tackle various practice exercises based on what we've learned so far. This will pave the way towards a deeper understanding of hash tables, their implementation in Python, and how they can be employed to solve different problems. Keep learning, and keep growing!